💥 LiteLLM Server - Deploy LiteLLM
A simple, fast, and lightweight OpenAI-compatible server to call 100+ LLM APIs in the OpenAI Input/Output format
Endpoints:
/chat/completions- chat completions endpoint to call 100+ LLMs/models- available models on server


![]()
Local Usage
$ git clone https://github.com/BerriAI/litellm.git
$ cd ./litellm/litellm_server
$ uvicorn main:app --host 0.0.0.0 --port 8000
Test Request
Ensure your API keys are set in the Environment for these requests
- OpenAI
- Azure
- Anthropic
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "azure/<your-deployment-name>",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "claude-2",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7,
}'
Setting LLM API keys
This server allows two ways of passing API keys to litellm
- Environment Variables - This server by default assumes the LLM API Keys are stored in the environment variables
- Dynamic Variables passed to
/chat/completions- Set
AUTH_STRATEGY=DYNAMICin the Environment - Pass required auth params
api_key,api_base,api_versionwith the request params
- Set
Deploy on Google Cloud Run
Click the button to deploy to Google Cloud Run
On a successfull deploy your Cloud Run Shell will have this output
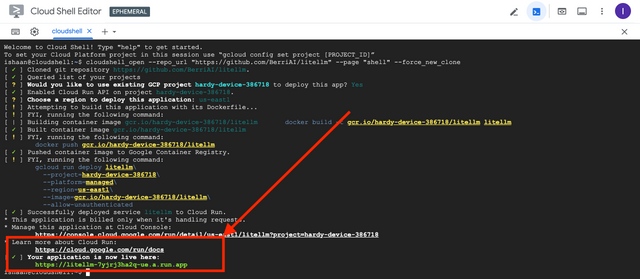
Testing your deployed server
Assuming the required keys are set as Environment Variables
https://litellm-7yjrj3ha2q-uc.a.run.app is our example server, substitute it with your deployed cloud run app
- OpenAI
- Azure
- Anthropic
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "azure/<your-deployment-name>",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
curl https://litellm-7yjrj3ha2q-uc.a.run.app/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "claude-2",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7,
}'
Set LLM API Keys
Environment Variables
More info here
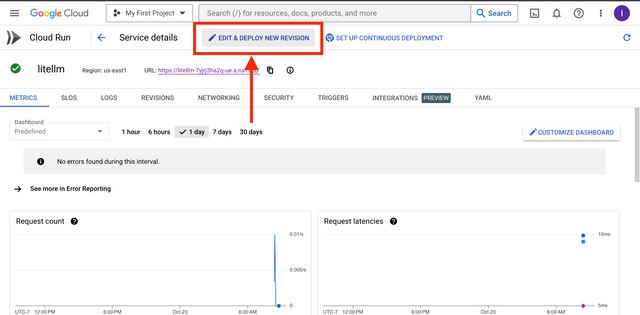
In the Google Cloud console, go to Cloud Run: Go to Cloud Run
Click on the litellm service

Click Edit and Deploy New Revision
Enter your Environment Variables Example
OPENAI_API_KEY,ANTHROPIC_API_KEY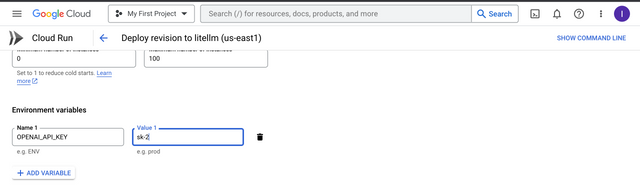
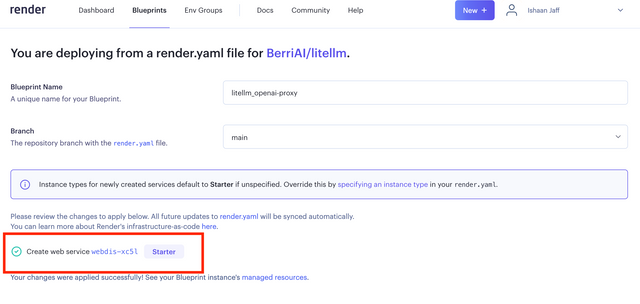
Deploy on Render
Click the button to deploy to Render
On a successfull deploy https://dashboard.render.com/ should display the following
Deploy on AWS Apprunner
Fork LiteLLM https://github.com/BerriAI/litellm
Navigate to to App Runner on AWS Console: https://console.aws.amazon.com/apprunner/home#/services
Follow the steps in the video below
Testing your deployed endpoint
Assuming the required keys are set as Environment Variables Example:
OPENAI_API_KEYhttps://b2w6emmkzp.us-east-1.awsapprunner.com is our example server, substitute it with your deployed apprunner endpoint
- OpenAI
- Azure
- Anthropic
curl https://b2w6emmkzp.us-east-1.awsapprunner.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'curl https://b2w6emmkzp.us-east-1.awsapprunner.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "azure/<your-deployment-name>",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'curl https://b2w6emmkzp.us-east-1.awsapprunner.com/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "claude-2",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7,
}'
Advanced
Caching - Completion() and Embedding() Responses
Enable caching by adding the following credentials to your server environment
REDIS_HOST = "" # REDIS_HOST='redis-18841.c274.us-east-1-3.ec2.cloud.redislabs.com'
REDIS_PORT = "" # REDIS_PORT='18841'
REDIS_PASSWORD = "" # REDIS_PASSWORD='liteLlmIsAmazing'
Test Caching
Send the same request twice:
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7
}'
curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7
}'
Control caching per completion request
Caching can be switched on/off per /chat/completions request
- Caching on for completion - pass
caching=True:curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7,
"caching": true
}' - Caching off for completion - pass
caching=False:curl http://0.0.0.0:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "write a poem about litellm!"}],
"temperature": 0.7,
"caching": false
}'